Media Summary: In this talk we present how we trained a 530B parameter Episode 83 of the Stanford MLSys Seminar Series! ML Performance Reading Group Session 8, where we covered the paper "
Overview
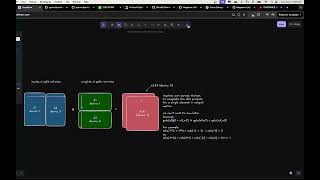
Efficient Large Scale Language Model Training On Gpu Clusters Using Megatron Lm - Detailed Analysis
In this talk we present how we trained a 530B parameter Episode 83 of the Stanford MLSys Seminar Series! ML Performance Reading Group Session 8, where we covered the paper " After 6+ months in the making and burning over a year of Let's talk about an intriguing topic today, diving into the world of For more information about Stanford's online Artificial Intelligence programs visit: To learn more about ...
Today we're joined by Bryan Catanzaro, vice president of applied deep learning research at NVIDIA. Most folks know Bryan as ... We live in a world where hyperscale systems for machine intelligence are increasingly being used to solve complex problems ...
Gallery
Photo Gallery









![[Paper Review] Megatron-LM](https://i.ytimg.com/vi/Q8RSo0m9BUs/mqdefault.jpg)

Related


